목차
반응형

1. 설치
- anaconda 설치
conda install conda-forge::mlflow
- pip 설치
pip install mlflow
2. MLflow로 할 수 있는 일 요약
- 실험 추적(MLflow Tracking): MLflow Tracking을 사용하면 머신러닝 실험의 매개변수, 코드 버전, 메트릭 및 결과 파일(예: 모델)을 기록하고 비교
- 프로젝트(MLflow Projects): MLflow Projects는 머신러닝 코드를 패키징하고 재사용할 수 있는 방법을 제공
- 모델 관리(MLflow Models): MLflow Models는 머신러닝 모델을 다양한 ML 라이브러리에서 사용할 수 있는 표준 포맷으로 패키징
- 모델 서빙(MLflow Model Serving): MLflow를 사용하면 학습된 모델을 실시간으로 예측 서비스로 배포
- 모델 레지스트리(MLflow Model Registry): 모델 레지스트리를 사용하면 모델의 전체 생명주기를 관리
3. 간단한 사용 예시 (실험 추적)
3.1. 간단한 실험하기
import mlflow
import mlflow.sklearn
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 데이터셋 로드
boston = load_boston()
X = boston.data
y = boston.target
# 데이터를 학습 세트와 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# MLflow 실험 시작
mlflow.start_run()
# 모델 학습
model = LinearRegression()
model.fit(X_train, y_train)
# 예측 및 메트릭 계산
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
# 매개변수, 메트릭, 모델 기록
mlflow.log_param("model_type", "linear_regression")
mlflow.log_metric("mse", mse)
# 모델 저장
mlflow.sklearn.log_model(model, "model")
# MLflow 실험 종료
mlflow.end_run()
1. MLflow 실험 시작합니다.
mlflow.start_run()
2. 매개변수, 메트릭 저장
mlflow.log_param()
mlflow.log_metric()
3. 모델 저장
mlflow.sklearn.log_model(model, "model")
4. MLflow 실험 종료
mlflow.end_run()
3.2. ui 실행
실험을 실행한 후 MLflow UI를 사용하여 기록된 실험 결과를 볼 수 있습니다. MLflow UI를 시작하려면 터미널에서 다음 명령어를 실행하세요
mlflow ui
이후에 크롬에서 http://127.0.0.1:5000 를 입력하고 들어가 봅시다.
아래와 같이 페이지가 나오면 성공입니다!
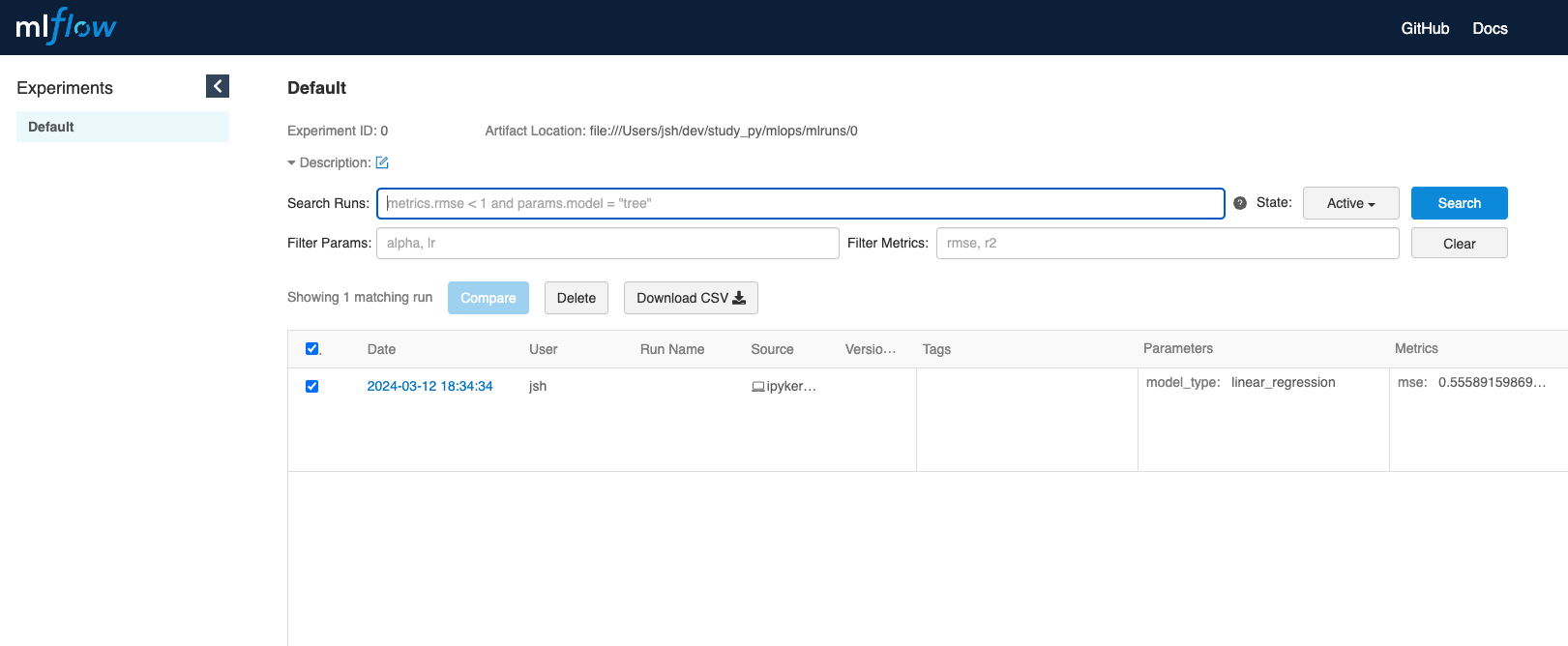
반응형
'MLOps' 카테고리의 다른 글
| 쿠버네티스(kubenetes)에 데이터베이스 추가하기 (4) | 2024.03.28 |
|---|---|
| 쿠버네티스(Kubernetes) 기본적인 사용 방법 (1) | 2024.03.28 |
| 쿠버네티스(Kubernetes) 설치와 실행 방법 (1) | 2024.03.19 |
| 쿠버네티스(Kubernetes)란! 왜 사용하는 것일까? (0) | 2024.03.19 |
| [Data Lake] 데이터 레이크 설명 (1) | 2021.05.18 |