목차
반응형
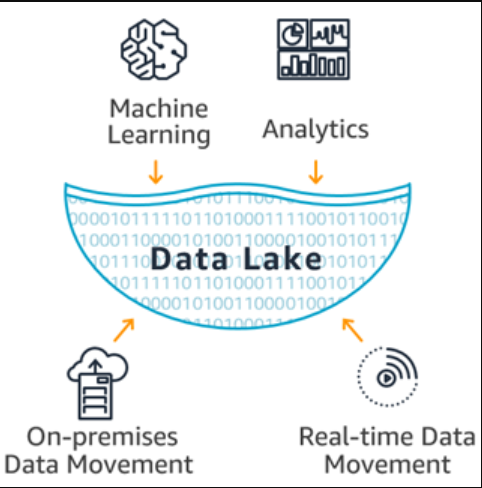
1. 데이터 레이크는 왜 필요할까?
- 데이터의 양이 많지 않고 앞으로도 쌓일 데이터가 없을 것이라고 예상된다면, 데이터 레이크는 필요하지 않다. 그러나 빅데이터가 존재하는 곳이라면 데이터레이크는 필수적이다.
- 지금은 데이터가 곧 돈이 되는 정보화 시대이다. 생성된 데이터를 그냥 버리는 것이 아니라, 잘 정리해서 모아두는 것이 현 시대에 아주 중요한 일이 아닐 수 없다.
2. 데이터 레이크란
2.1. 목적
- 데이터 분석을 위해 데이터를 쌓음
- 인공지능 학습을 위해 데이터를 쌓음
2.2. 특징
- Raw 데이터를 있는 그대로 저징해 두는 저장소
- 대용량 데이터
- 정형/비정형 데이터 모두 저장
- 중앙 집중식 저장소
- 분산 시스템
2.3. 단점
- 관리하기가 복잡하다
- 데이터 사용시 변형을 해야한다.
3. 제품
3.1. 클라우드 제품
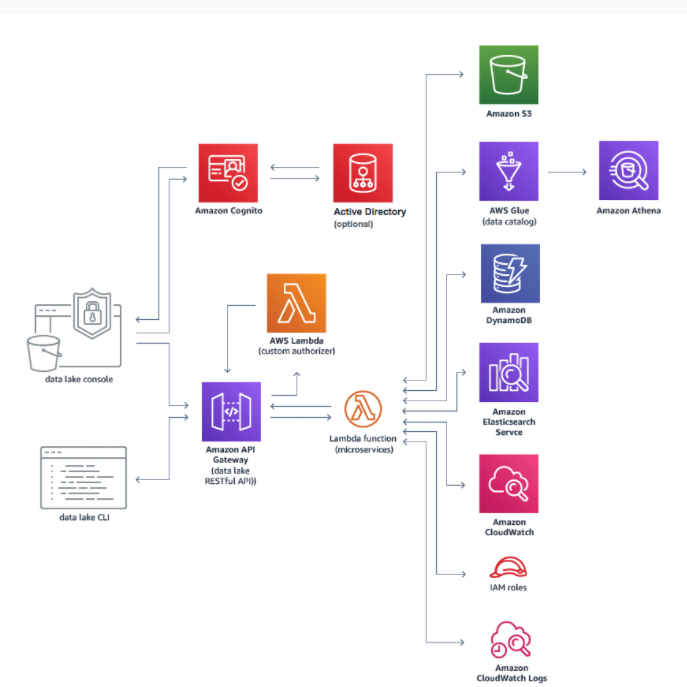
- AWS lake Formation
- S3에 데이터 저장
- AWS Glue를 통한 ETL
- AWS Lambda로 컴퓨팅 리소스를 자동으로 관리
- Google Cloude Storage
- Cloud Storage에 데이터 저장
3.2. 오픈 소스
- Hadoop
4. Data Lake 사용 방법
- ETL 과정을 통해 데이터를 정제해서 사용한다. (ETL도 여러 제품이 존재한다.)
반응형
'MLOps' 카테고리의 다른 글
| 쿠버네티스(kubenetes)에 데이터베이스 추가하기 (2) | 2024.03.28 |
|---|---|
| 쿠버네티스(Kubernetes) 기본적인 사용 방법 (1) | 2024.03.28 |
| 쿠버네티스(Kubernetes) 설치와 실행 방법 (0) | 2024.03.19 |
| 쿠버네티스(Kubernetes)란! 왜 사용하는 것일까? (0) | 2024.03.19 |
| MLflow 처음 시작하기 (0) | 2024.03.12 |