목차
반응형

1. 개요
이번 포스팅에서는
HuggingFace에서 제공하는
프레임워크에 대해 소개하겠다.
| 라이브러리 | 역할 | 주요 기능 |
| Transformers | 모델, 토크나이저 | AutoModel, AutoTokenizer 등 |
| Trainer | 지도학습 (SFT) | Trainer, TrainingArguments |
| TRL | 강화학습 (RLHF) | PPOTrainer, SFTTrainer |
| DeepSpeed | GPU 메모리 최적화 | ZeRO Stage, Hugging Face Trainer와 연동 |
| Accelerate | 분산 학습 최적화 | 여러 GPU/TPU 환경에서 Trainer 가속화 |
| PEFT (Parameter Efficient Fine-Tuning) | 파라미터 효율적 파인튜닝 기법 지원 | LoraConfig, get_peft_model |
| Evaluate | 모델 평가 | load_metric("bleu"), compute() |
세가지 단계에 걸쳐 학습을 진행한다.
- 학습 설정 (TrainingArguments)
- Trainer 설정
- 학습 실행
2. TrainingArguments
2.1. 설명
TrainingArguments는 학습을 제어하는 핵심 설정을 담당하는 클래스 이다. (출처 : huggingface)
2.1.1. 기본 학습 설정
| 옵션 | 설명 | 기본값 | 설정추천 |
| output_dir | 모델 체크포인트 저장 디렉토리 | 필수 | V |
| overwrite_output_dir | 기존 체크포인트 엎어쓰기 여부 | False | |
| num_train_epochs | 학습 에포크 수 | 3 | |
| max_steps | 최대 학습 스탭(설정하면 num_train_epochs 무시) | -1 (제한없음) | V |
| per_device_train_batch_size | GPU당 학습 배치 크기 | 8 | V |
| per_device_eval_batch_size | GPU당 평가 배치 크기 | 8 | V |
| gradient_accumulation_steps | Gradient Accumulation 스탭 수 | 1 | |
| gradient_checkpointing | Gradient Checkpointing 활성화 | False |
2.1.2. 평가(Evalueation) 및 로깅 설정
| 옵션 | 설명 | 기본값 | 설정추천 |
| evaluation_strategy | 평가 실행 시점 ("no", "steps", "epoch") | "no" | V |
| eval_steps | 평가를 수행할 스탭 간격 (사용시 evaluation_strategy="steps") | 500 | |
| logging_dir | TensorBoard 로그 저장 디렉토리 | "runs" | |
| logging_strategy | 로깅 실행 시점 ("no", "steps", "epoch") | "steps" | V |
| logging_steps | 로그 출력 간격 (stpep 단위) | 500 | |
| save_strategy | 체크포인트 저장 주기 ("no", "steps", "epoch") | "steps" | V |
| save_steps | 체크포인트 저장 주기 (step 단위, ) | 500 | |
| save_total_limit | 저장할 체크포인트 개수 (최신 N개 유지) | None |
2.1.3. 옵티마이저 및 학습 스케줄링
| 옵션 | 설명 | 기본값 | 설정추천 |
| learning_rate | 학습률 | 5e-5 | |
| weight_decay | L2 정규화 계수 | 0 | |
| adam_beta1 | Adam 옵티마이저의 beta1 값 | 0.9 | |
| adam_beta2 | Adam 옵티마이저의 beta2 값 | 0.99 | |
| adam_epsilon | Adam 옵티마이저의 epsilon 값 | 1e-8 | |
| max_grad_norm | Gradient Clipping 값 | 1.0 | |
| lr_scheduler_type | 학습 스케줄러 (linear, cosine, constant, polynomial) | "linear" | |
| warmup_steps | Warmup 스텝 수 | 0 | |
| warmup_ratio | 전체 스탭 대비 Warmup 비율 | 0.0 |
2.1.4. Mixed Precision (FP16, BF16) 및 GPU 최적화
| 옵션 | 설명 | 기본값 | 설정추천 |
| fp16 | - True인 경우 가중치(weight), 활성화값(activation), 연산(operation)을 FP16 형식으로 변환 - False인 경우 fp32 를 사용함 - GPU가 FP16을 지원하는 경우 (NVIDIA Volta 이상) 사용 - 16이 32 보다 적은 양의 메모리를 사용한다. |
False | |
| bf16 | - True인 경우 bf16 사용 - False인 경우 fp32 를 사용함 - NVIDIA Ampere (A100, RTX 30XX) 이상에서 학습할 때 bf16이 FP16보다 더 안정적 - Gradient Scaling 없이도 사용 가능 → 모델 수렴이 더 쉬움 - Ampere 이전의 GPU (V100, RTX 20XX, GTX 시리즈)에서는 지원되지 않음 - FP16보다 메모리 절약 효과가 낮을 수도 있음 |
False | |
| fp16_opt_level | - Apex AMP 최적화 레벨 ( "O0" , "O1", "O2", "O3") - 일반적으로 "O1"로 하는게 좋음 |
"O1" | |
| fp16_full_eval | - 평가 시에 FP16 사용 - 평가 속도를 높이고 싶은 경우 |
False | |
| half_precision_backend | - "auto" : 별일 없으면 auto로 하자 - "apex" : NVIDIA의 apex 라이브러리 사용 (수동 설치 필요) - "amp" : PyTorch의 기본 AMP (Automatic Mixed Precision) 사용 |
"auto" |
2.1.5. 분산 학습 & FSDP 설정
기본적으로 GPU가 2개 이상일 때 사용한다.
- GPU가 2개 이상 : FSDP / DDP
- GPU가 8개 이상 : FSDP + ZeRO (DeepSpeed)
| 옵션 | 설명 | 기본값 | 설정추천 |
| ddp_backend | - 멀티 GPU 분산 학습용 - "nccl", "gloo", "mpi" |
"nccl" | |
| fsdp | - Fully Sharded Data Parallel 활성화 - "full_shard", "auto_wrap", "offload" |
"None" | |
| fsdp_offload_params | CPU로 일부 파라미터 오프로딩 | False | |
| fsdp_transformer_layer_cls_to_wrap | FSDP를 적용할 Transformer 레이어 클래스 이름 | None |
2.1.6. Checkpoint & Resume 설정
| 옵션 | 설명 | 기본값 | 설정추천 |
| resume_from_checkpoint | 체크포인트에서 학습 재개 | None | |
| save_on_each_node | 노드마다 개별적으로 체크포인트 저장 | False |
2.1.7. TPU & Multi-GPU 관련 설정
| 옵션 | 설명 | 기본값 | 설정추천 |
| tpu_num_cores | TPU 코어 개수 | None | |
| dataloader_num_workers | DataLoader의 병렬 처리 워커 수 | 0 | |
| dataloader_pin_memory | DataLoader에서 GPU에 데이터를 핀(Pin)할지 여부 | True |
2.1.8. WandB, TensorBoard, Comet 로깅 설정
| 옵션 | 설명 | 기본값 | 설정추천 |
| report_to | 로깅할 서비스 ("wandb", "tensorboard", "comet_ml", "none") | "none" | |
| run_name | 실험 이름 (WandB, TensorBoard 용) | None | |
| disable_tqdm | True로 설정하면 tqdm 로그 출력 비활성화 | False |
2.2. 기본 사용법
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./results", # 모델 저장 경로
evaluation_strategy="epoch", # 평가 주기 (매 epoch마다 평가)
save_strategy="epoch", # 체크포인트 저장 주기
per_device_train_batch_size=8, # 학습 배치 크기
per_device_eval_batch_size=8, # 평가 배치 크기
num_train_epochs=3, # 학습 epoch 수
weight_decay=0.01, # L2 정규화 (Weight Decay)
logging_dir="./logs", # 로그 저장 경로
logging_strategy="epoch", # 로그 저장 주기
save_total_limit=2, # 저장할 체크포인트 개수 제한
push_to_hub=False, # 모델을 Hugging Face Hub에 업로드할지 여부
)
3. Trainer
3.1. Trainer 설명
transformers.Trainer는 Hugging Face의 transformers 라이브러리에서 제공하는 학습 도구로, 모델 학습을 편리하게 관리할 수 있다.
Trainer 설정 (Trainer 설명 출처 링크)
from transformers import Trainer
trainer = Trainer(
model=model, # 학습할 모델
args=training_args, # 학습 설정 (TrainingArguments)
train_dataset=train_dataset, # 학습 데이터셋 (Dataset 객체)
eval_dataset=eval_dataset, # 평가 데이터셋 (Dataset 객체)
tokenizer=tokenizer, # 토크나이저 (필요할 경우)
data_collator=data_collator, # 배치 데이터 처리 (옵션)
compute_metrics=compute_metrics, # 평가 지표 계산 (옵션)
)
학습 실행
trainer.train()
3.2. train() 추가 옵션
체크포인트에서 다시 학습하기
trainer.train(resume_from_checkpoint=True)
모델 저장 및 로드
trainer.save_model("./my_model") # 모델 저장
model = AutoModelForSequenceClassification.from_pretrained("./my_model") # 저장된 모델 로드
4. 커스텀 metric 추가
- datasets.load_metric 에서 기본 metric 제공
- compute_metrics 에 평가 함수 추가
import numpy as np
import evaluate # 🤗 evaluate 라이브러리 사용
accuracy = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return accuracy.compute(predictions=predictions, references=labels)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
compute_metrics=compute_metrics, # 평가 함수 추가
)
datasets.load_metric()에서 지원되는 metric 종류
- accuracy (정확도)
- f1 (F1-score)
- precision (정밀도)
- recall (재현율)
- roc_auc (ROC AUC)
- bleu (BLEU - 번역 성능 평가)
- wer (Word Error Rate - 음성 인식 평가)
- mse (Mean Squared Error - 회귀 문제)
5. TRL
TRL (Transformer Reinforcement Learning)은
Hugging Face가 제공하는 강화학습(Reinforcement Learning) 기반 언어모델 트레이닝 라이브러리이다.
다양한 trainer를 제공하고 있으며, 사용방법은 간단하기 때문에
불러와서 사용하면 되겠다.
아래 경로로 가서 확인해 보자
- 왼쪽 목차 > API > Trainers > 원하는 trainer 클릭
TRL - Transformer Reinforcement Learning
huggingface.co
trainer를 선택해 들어가면 아래와 같이
실행할 수 있는 코드와
파라미터를 정리해둔 문서가 있다.
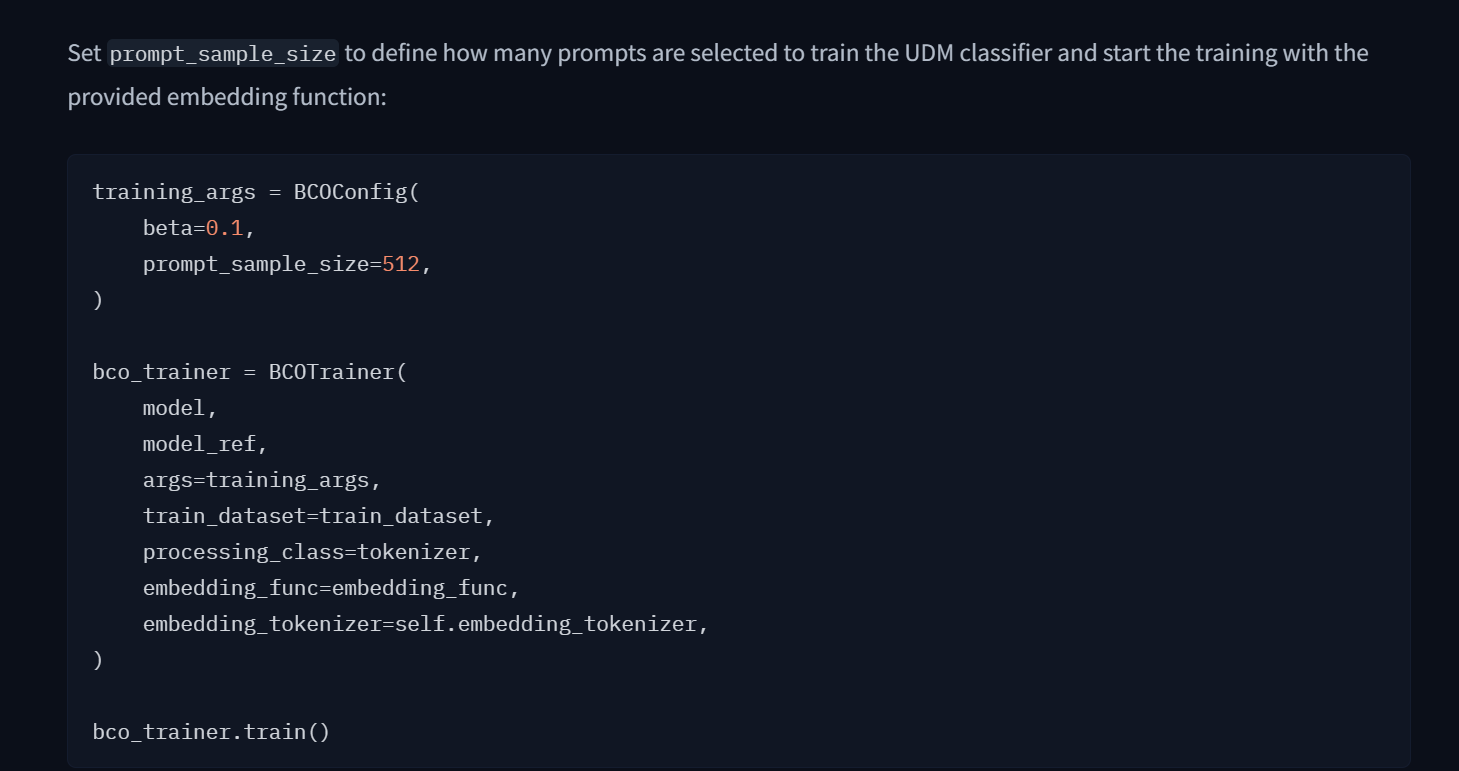
deepSpeed 부터는 다음 포스팅에서 설명하겠다.
반응형
'자연어처리 > LLM을 위한 코딩' 카테고리의 다른 글
| [LLM] 모델 학습 with HuggingFace (DeepSpeed) (7) (0) | 2025.02.20 |
|---|---|
| [LLM] 모델 학습 with HuggingFace (Accelerate) (6) (0) | 2025.02.15 |
| [LLM] 데이터 준비 with huggingface (datasets) (4) (0) | 2025.02.10 |
| LLM 모델 불러오기 실행하기 (Huggingface Transformers) (3) (2) | 2025.01.28 |
| Pytorch Transformers 설치 (2) (1) | 2025.01.28 |