목차

0. 개요
0.1. 왜 사용하는가
채팅 서버를 관리하다 보면
유저들이 어떠한 질문을 채팅모델에 던지는지
궁금해지기 마련이다.
그렇지만 데이터가 수십만개가 넘어 가면
유저들이 어떠한 질문을 하는지 파악하기가 어려워 진다.
이번 포스팅 에서는 군집분석(Clustering)을 통해
유저의 질문 데이터를 비슷한 데이터끼리 묶어주고
토픽을 찾아 볼 것이다.
관련 모델은
BERTopic 이 있다.
이 모델을 이용해
질문 데이터에서 토픽을 추출해 보자.
0.2. 분석 순서
BERTopic의 분석 순서는 다음과 같다.
1. 문장 벡터화 (Sentence Embedding)
2. 클러스터링 (HDBSCAN)
3. 토픽 추출 (TF-IDF & c-TF-IDF)
4. 결과 시각화 및 분석
1. 문장 벡터화
먼저, 문자열 형태의 데이터는 임베딩(Embedding) 모델을 통해 벡터화 시켜야 한다.
벡터화된 데이터는 거리가 가까울 수록 의미가 가깝기 때문에
수치적으로 분석할 수 있기 때문이다.
임베딩에 대한 자세한 설명은 이전 포스팅에서 확인해 보자 (링크)
[Langchain] 임베딩(Embedding)과 유사도 검색 방법 for Retriever
1. 임베딩(Embedding)정의 : 임베딩은 단어, 문장, 이미지 등과 같은 데이터를 숫자 벡터(연속된 실수 공간)로 표현하는 방식 단어나 문장을 임베딩 모델(BERT, GPT 등)을 통해 고정된 차원의 실수 벡터
databoom.tistory.com
이번 포스팅에는 HuggingFace에 있는 bge-m3 모델을 사용해 보겠다.
HuggingFace는 sentence_transformers 라이브러리로 embedding 모델을 지원한다. (성능이 안좋다면 유료 모델을 사용해도 좋다.)
from sentence_transformers import SentenceTransformer
embedding_model = SentenceTransformer("BAAI/bge-m3")
2. 클러스터링(HDBSCAN)
2.1. HDBSCAN 개념
BERTopic 모델은 HDBSCAN를 사용해 벡터 데이터를 군집화 한다.
HDBSCAN (Hierarchical DBSCAN)는 DBSCAN (Density-Based Spatial Clustering of Applications with Noise)의 확장된 형태로 밀도 기반 클러스터링 기법을 사용하여 데이터를 군집화한다.
위에서 만든 벡터화 시긴 데이터에서
밀도가 높은 지역을 클러스터로 간주하고, 밀도가 낮은 지역은 노이즈로 간주하는 방식으로 작동한다.
2.2. HDBSCAN 특징
- 밀도 기반 군집화: 같은 군집에 속한 데이터는 서로 가까운 거리에 있으며, 이들이 밀도가 높은 지역에 위치한다고 가정
- 계층적 군집화: DBSCAN과 달리, HDBSCAN은 계층적 클러스터 트리를 생성하고, 이를 통해 군집의 수를 자동으로 결정
- 클러스터의 안정성: 군집을 형성할 때, 각 군집의 "안정성" 을 평가하여 더 중요한 군집을 추출
- 노이즈 처리: DBSCAN처럼 HDBSCAN도 노이즈 데이터를 처리
2.3. 상세 설명
HDBSCAN 은 3단계로 동작한다.
2.3.1. 각 데이터 포인트의 코어 거리를 계산한다.
- \( Eps \) : 점으로 부터의 반경
- \( minPts \) : 반경 Eps 인 원을 그렸을 때 그 점이 코어 점 (core points), 군집이 되기 위해 Eps 안에 필요한 최소한의 점 개수
- \( distance(a, b) \) : a, b 사이의 거리
$$ core\ distance(x_i) = distance(x_i, minPts 번째 점) $$
2.3.2. 상호 도달 거리(Mutual Reachability Distance)를 계산한다.
상호 도달 거리는 두 점이 얼마나 밀접하게 연결되어 있는지를 측정한다.
$$ mrd(x_i, x_j) = max(core\ distance(x_i), core\ distance(x_j), distance(x_i, x_j) ) $$
2.3.3. 계층적 클러스터 트리(Hierarchical Cluster Tree)
트리의 각 노드는 군집이다.
상호 도달 거리를 기준으로
클러스터가 계속해서 병합되거나 분리
이후, 클러스터가 변하지 않고 안정적이 되면
최종적으로 클러스터를 선택한다.
2.4. 예시 코드
import hdbscan
hdbscan_model = hdbscan.HDBSCAN(
min_cluster_size=5, # 클러스터 최소 크기
min_samples=2, # 최소 샘플 수
metric="euclidean",
cluster_selection_method="eom"
)
3. Vectorizer Model
각 클러스터에서 가장 중요한 단어(키워드)를 추출하는 데 사용
단순히 문장 임베딩 벡터만 있으면 이 토픽이 무슨 내용인지 알기가 어렵기 때문
3.1. TF-IDF
기존 TF-IDF(Term Frequency - Inverse Document Frequency)는 개별 문서에서 중요한 단어를 찾는데 사용
- TF (Term Frequency): 단어 w가 문서 d에서 얼마나 자주 등장하는지
- IDF (Inverse Document Frequency): 해당 단어가 전체 문서에서 얼마나 희귀한지
3.2. c-TF-IDF
c-TF-IDF는 군집(클러스터) 전체를 하나의 문서처럼 취급
군집 내에서 중요한 단어를 찾고,
다른 군집과 비교하여 특징적인 단어를 강조
수식 요소
- \( w \) : 특정 단어 (word)
- \( C \) : 특정 클러스터 (군집, class)
- \( f(w, C) \) : 군집 \( C \) 내에서 단어 \( w \)가 등장하는 총 빈도수
- \( |C| \) : 군집 \( C \) 내의 전체 단어 수 (즉, 군집의 길이)
- \( N \) : 전체 문서 수
- \( \sum_{C' \neq C} f(w, C') \) : 다른 군집들에서 단어 \( w \)가 등장하는 총 빈도수
TF 수식과 설명
- w(단어)가 등장한 빈도수 / 군집의 크기
$$ \frac{f(w, C)}{|C|} $$
IDF 수식과 설명
- 문서(N)에 w가 많이 등장할 수록 IDF 값이 작아짐
- 반대로 적게 등장할 수록 IDF 값이 높아짐
- 로그를 사용하면 값이 극단적으로 커지는 것을 막아줌
- 즉 전체 문서에서 희소한 단어일 수록 값을 작게 만들어줌
$$ \log \left( \frac{N}{\sum_{C' \neq C} f(w, C')} \right) $$
전체 수식
$$ cTFIDF(w, C) = \frac{f(w, C)}{|C|} \times \log \left( \frac{N}{\sum_{C' \neq C} f(w, C')} \right) $$
3.3. 예시 코드
불용어는 적절히 추가해 주자.
from sklearn.feature_extraction.text import CountVectorizer
# 불용어 처리 (한국어 불용어 추가 가능)
stop_words = ["많은",] # 한국어 불용어
# CountVectorizer 설정 (bigram 사용)
vectorizer_model = CountVectorizer(ngram_range=(1, 3), stop_words=stop_words, min_df=1, max_df=0.9)
4. BERTopic 예시 코드
BERTopic 모델을 사용하면
embedding 모델, hdscan 모델, vectorizer 모델을 설정할 수 있다.
from bertopic import BERTopic
# BERTopic 모델 생성
topic_model = BERTopic(
embedding_model=embedding_model,
vectorizer_model=vectorizer_model,
hdbscan_model=hdbscan_model,
min_topic_size=1, # 최소 1개 이상의 문장을 포함한 토픽만 생성
verbose=True
)
모델링 수행
- nr_topics은, 토픽을 줄일 개수를 의미한다. (노이즈 포함이므로 3개의 토픽을 만들 경우 4로 한다)
# 6. 토픽 모델링 수행
topics, probs = topic_model.fit_transform(documents)
topic_model.reduce_topics(documents, nr_topics=4)
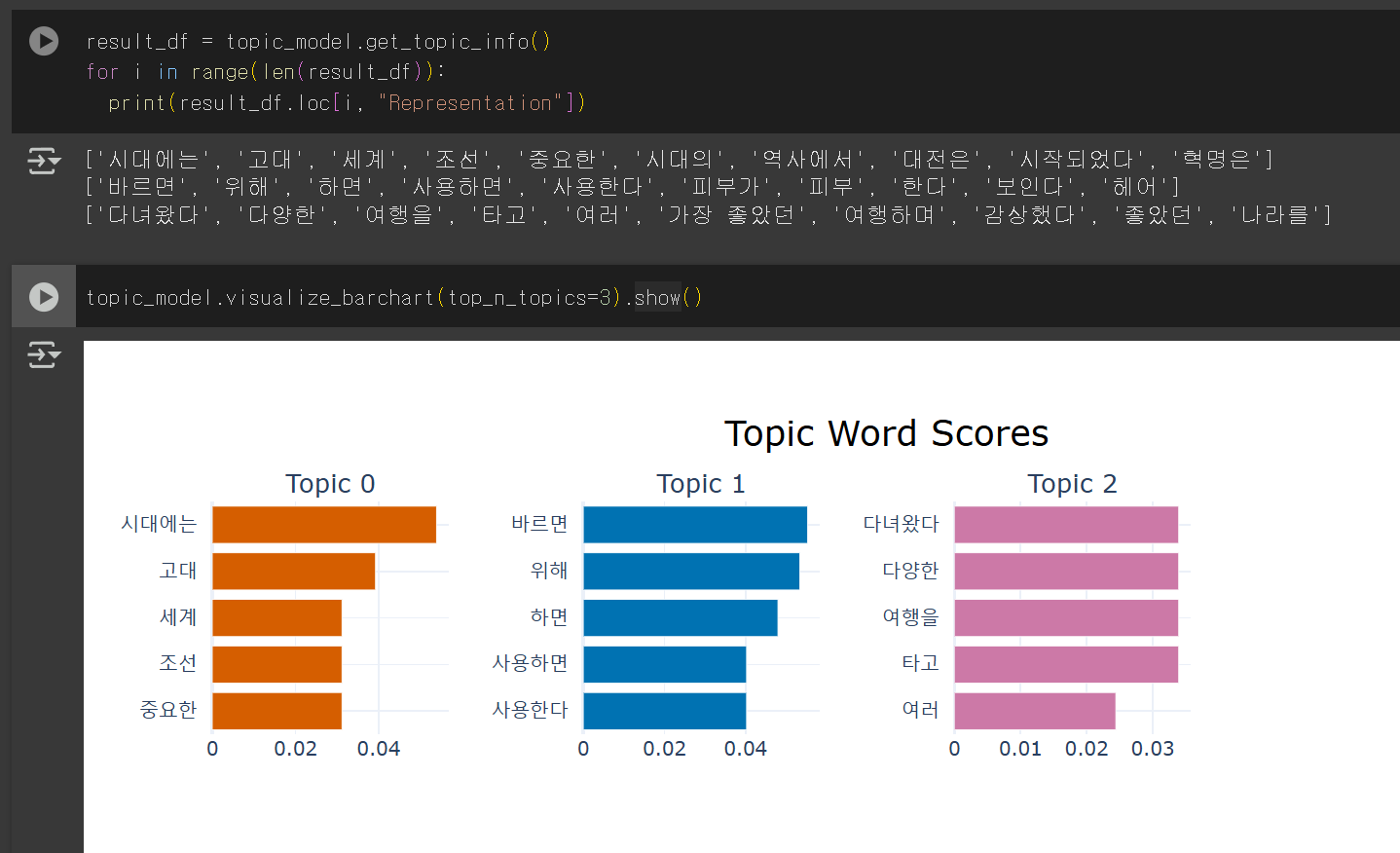
결과 출력
topic_model.get_topic_info()
결과 시각화
topic_model.visualize_barchart(top_n_topics=3).show()
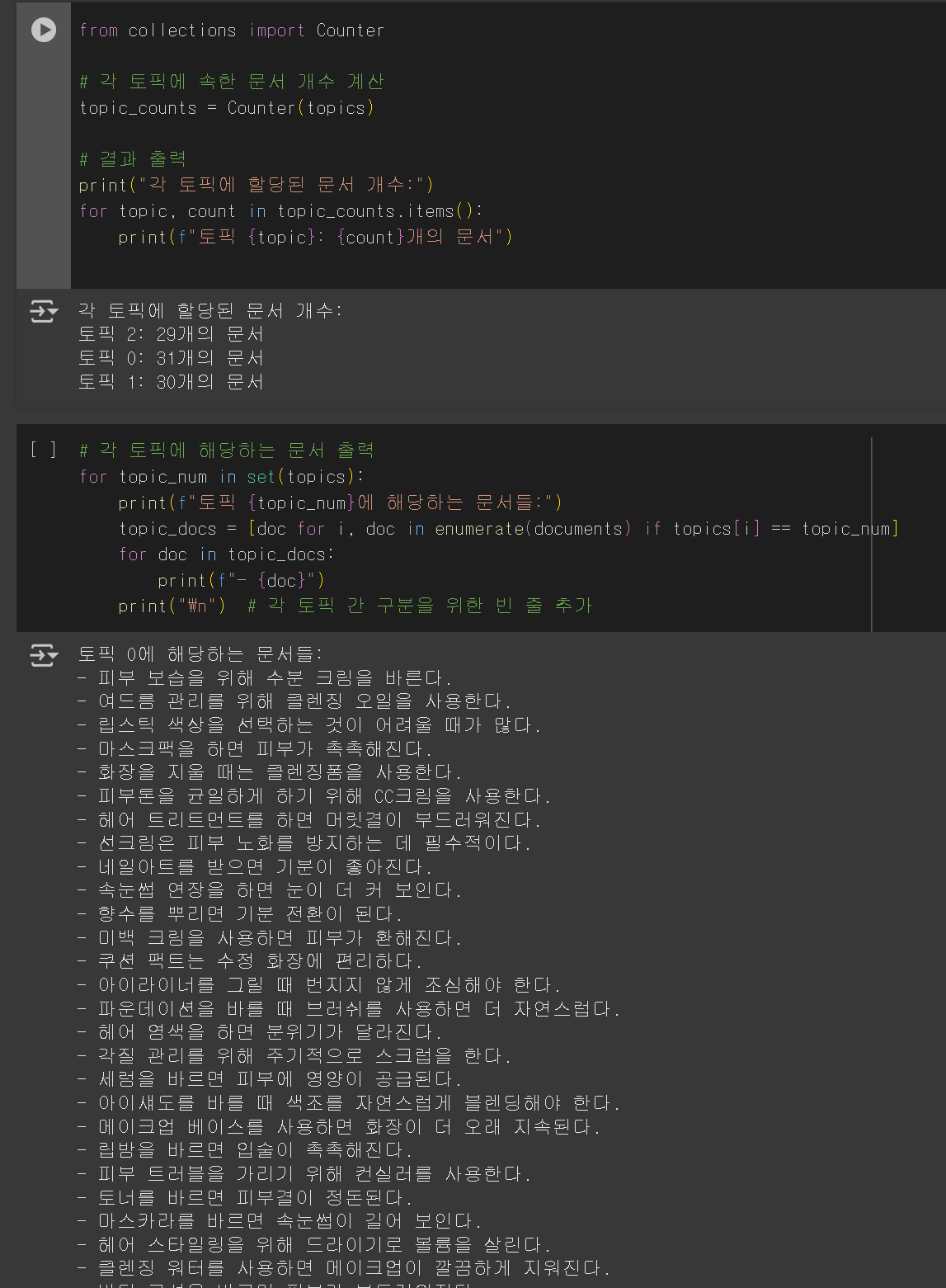
5. 결과
- 필자는 여행, 미용, 역사 세가지 주제의 데이터 30개씩 모아 모델링을 진행했다.
- 실행 결과 1개의 문장 빼고 모두 정확히 분류한 것을 확인했다.
- 파라미터를 어떻게 적용하느냐, 임베딩 모델을 좋을 것을 쓰느냐, 데이터 숫자가 충분한가에 따라 성능이 크게 차이가 났다.
colab으로 링크를 공유해 둘테니
필요한 사람은 아래
하트를 누르고
댓글도 적고
사용하길 바란다.
https://colab.research.google.com/drive/1YUbeyEuGUS--tYdbKDAtOkLhZGMbQ4l9?usp=sharing
'자연어처리 > Langchain' 카테고리의 다른 글
| [Langchain] VecterStore 사용하기 (2) | 2025.03.10 |
|---|---|
| [Langchain] Custom Retriever 만들기 (0) | 2025.03.09 |
| [Langchain] RAG 성능 평가 with Regas (0) | 2025.03.07 |
| [Langchain] 임베딩(Embedding)과 유사도 검색 방법 for Retriever (0) | 2025.03.06 |
| [Langchain] Retriever 사용하기 (3) | 2025.03.05 |