자연어처리/LLM 모델
[LLM] Llama2 - 논문 요약 (2)
Suda_777
2024. 9. 11. 12:01
반응형

논문 제목 : Llama 2: Open Foundation and Fine-Tuned Chat Models (논문링크)
발행연도: 2023
0. Abstract
- Llama2는 파라미터가 70억~700억개로, 거대 모델이다.
- 사람의 평가를 기반으로 함 (도움이 되는지, 안전한지)
- 상세한 모델 사용법을 제공한다.
1. Introduction
- 거대 언어 모델(Large Language Models, LLMs)은 전문적인 지식을 요구하는 다양한 분야서 AI 시스턴트로서의 가능성을 보여주고 있음
- Reinforcement Learning with Human Feedback (RLHF): 사람의 피드백을 반영해 학습하는 기법
- 사전훈련 모델 공개되어 있음, 연구 및 상업용으로 일반 대중에게 공개
- Llama2
- Llama 1의 업데이트 버전, 훈련 말뭉치 크기를 40% 증가시키고 모델의 문맥 길이를 두 배로함.
- 그룹화된 쿼리 어텐션(Grouped-query attention, GQA)을 채택
- 34B 버전은 훈련했지만 공개하지는 않음
- Llama2-chat
- 대화용 사례에 최적화된 Llama 2의 파인튜닝 버전
- 7B, 13B 및 70B 파라미터 버전을 공개
- Llama2
- 파인튜닝 방법 안전성에 대한 설명을 제공함. 파인튜닝시 안정성 테스트 수행할 것.
2. Pretraining
2.1 Pretraining Data
- 공개된 데이터를 사용함.
- 개인정보 관련 데이터는 삭제함
- 2조 개의 토큰 데이터로 훈련
2.2 Training Details
- Llama 1과 비슷한 내용
- 표준 트랜스포머 아키텍처(Vaswani et al., 2017)를 사용
- RMSNorm을 사용하여 사전 정규화
- SwiGLU 활성화 함수(Shazeer, 2020)
- 회전 위치 임베딩(RoPE, Su et al. 2022)을 사용
- Llama 1와 다른 내용
- 그룹화된 쿼리 어텐션(GQA)
- 하이퍼 파라미터
- AdamW 옵티마이저(Loshchilov and Hutter, 2017)
- β1 = 0.9, β2 = 0.95, eps = 10^-5로 설정
- 웜업이 2000 단계인 코사인 학습률 스케줄을 사용
- 최종 학습률을 피크 학습률의 10%로 감소
- 가중치 감쇠는 0.1
- 그래디언트 클리핑은 1.0
- Llama 2 family of models
- 토큰 개수는 사전 훈련에서만 사용.
- 모든 모델은 배치사이즈: 4백만 토큰
- 34B와 70B는 향상된 추론 확장성을 위해 그룹화된 쿼리 어텐션(GQA)을 사용
2.2.1 Training Hardware & Carbon Footprint
학습 하드웨어: Meta의 연구용 슈퍼 클러스터(RSC)와 내부 제작 클러스터 두 가지 클러스터
- 인터커넥트 기술: RSC는 NVIDIA Quantum InfiniBand를 사용하고, 제작 클러스터는 상용 이더넷 스위치를 기반으로 한 RoCE(RDMA over converged Ethernet) 솔루션을 사용
- GPU 당 전력 소비량: GPU 당 전력 소비량 제한은 400W이며, 제작 클러스터는 350W
사전 훈련 중의 이산화탄소 (CO2) 배출량: 생략, 환경에 좋다는 이야기.
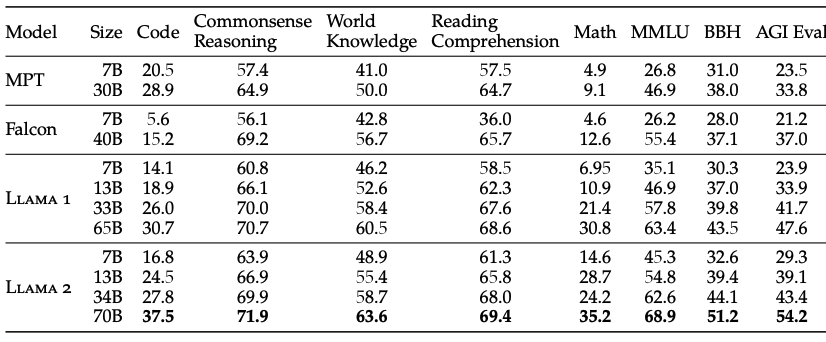
2.3. Llama 2 Pretrained Model Evaluation
- Code: 평균 pass@1 점수를 리포트함
- Commonsense Reasoning: PIQA, SIQA, HellaSwag, WinoGrande, ARC easy 및 challenge, OpenBookQA, CommonsenseQA 등의 평균
- World Knowledge: NaturalQuestions, TriviaQA에서 5-shot 성능 평가
- Reading Comprehension(읽기): SQuAD, QuAC, BoolQ에서 0-shot 성능 평가
- (Math)수학 : GSM8K, MATH
3. Fine-Tunning
- 아래 내용은 지도 학습을 통한 미세 조정(3.1 절) 및 초기 및 반복적인 보상 모델링(3.2.2 절) 및 RLHF(3.2.3 절)을 사용한 실험과 결과
- 추가적으로 Ghost Attention (GAtt) 설명
3.1. Supervised Fine-Tuning (SFT)

- 퀄리티가 제일 중요해
- 고품질의 제3자 지도 학습 데이터 수천 개의 예제를 수집하는 데 중점, 결과가 현저하게 향상
- 우리는 수만 개의 주석을 어노테이션한 결과가 높은 품질의 결과를 얻는 데 충분, 총 27,540개의 어노테이션을 수집한 후에 SFT 어노테이션을 중단 (메타 사용자 데이터는 포함하지 않았음)
- SFT 모델에서 샘플링한 출력이 종종 인간 어노테이터가 직접 작성한 SFT 데이터보다 경쟁력이 있음
- 파인튜닝 디테일
- 코사인 학습률 스케줄
- 초기 학습률은 2 × 10^(-5)
- 가중치 감소율은 0.1,
- 배치 크기는 64,
- 시퀀스 길이는 4096 토큰
- 모델 시퀀스 길이가 올바르게 채워지도록 하기 위해, 훈련 세트의 모든 프롬프트와 답변을 연결
- 특별한 토큰을 사용하여 프롬프트와 답변 세그먼트를 구분
- 답변 토큰에 대해서만 역전파를 수행.
3.2 Reinforcement Learning with Human Feedback (RLHF)
- 미세 조정된 언어 모델에 적용되는 모델 훈련 절차
- 모델의 행동을 인간의 선호 및 지시를 알아 차리도록
- 인간 어노테이터가 두 개의 모델 출력 중 어떤 것을 선호하는지 선택하는 방식으로 얻은 인간 선호를 대표하는 데이터를 수집
3.2.1 Human Preference Data Collection
- 어노테이터에게 먼저 프롬프트를 작성하도록 요청
- 참여자에게 강제 선택을 요청
- 선호 주석 데이터 수집에서 도움 및 안전성에 중점
- 새로운 샘플 분포에 노출되지 않으면 보상 모델 정확도가 빠르게 저하될 수 있음
3.2.2 Reward Modeling
- 도움과 안전성이 때로는 상충 관계
- 하나의 보상 모델이 두 가지 측면에서 모두 잘 수행하기가 어려움
- 두 개의 별도 보상 모델을 훈련
- 하나는 도움에 최적화된 모델 (Helpfulness RM)이며 다른 하나는 안전에 최적화된 모델 (Safety RM)

- 보상 모델은 사전 훈련된 언어 모델과 동일한 모델 아키텍처 및 하이퍼파라미터를 가지고 있지만, 다음 토큰 예측을 위한 분류 헤드 대신 스칼라 보상을 출력하기 위한 회귀 헤드로 대체, 채팅 모델과 보상 모델 간의 정보 불일치 방지
- Training Objectives
- binary ranking loss 사용
- rθ(x, y)는 모델 가중치 θ, 프롬프트 x 및 완성 y에 대한 스칼라
- yc는 어노테이터가 선택한 선호하는 응답
- yr은 거부
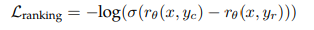
- 도움과 안전성 보상을 위해, 선호도 등급은 네 가지 포인트(예: 상당히 나은)의 스케일로 분해
- 손실에 여분의 마진 구성 요소를 추가
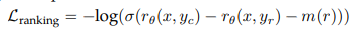
- m(r)은 선호도 등급의 이산 함수
- 서로 다른 응답을 가진 쌍에 대해 큰 마진을 사용하고, 유사한 응답을 가진 쌍에 대해서는 더 작은 마진을 사용
- Data Composition: meta가 믿는 데이터만 사용함
- 학습 디테일
- 훈련 데이터를 한 번의 에포크만 훈련, 훈련을 더 오래 진행하면 과적합
- 최대 학습률은 70B 파라미터 Llama 2-Chat에 대해 5 × 10^(-6)
- 나머지 모델에 대해 1 × 10^(-5)
- 최대 학습률의 10%로 줄어들도록 코사인 학습률 스케줄에 따라 감소
- 3%를 워밍업
- 최소값은 5
- 유효한 배치 크기는 고정된 512 쌍 또는 배치당 1024 행
- 보상 모델 결과
- 1000개의 예제를 테스트 세트로 사용
- gpt4 보다 좋다.
- 보상 모델을 위한 스케일링 트랜드
- 더 크고 많은 데이터가 정확도가 높다.
3.2.3 Iterative Fine-Tuning
- Proximal Policy Optimization (PPO)
- 사전에 훈련된 언어 모델은 최적화할 정책으로 작용
- Rejection Sampling
- 모델에서 K개의 출력을 샘플링하고 보상에 따라 최상의 후보를 선택
3.3 System Message for Multi-Turn Consistency
- 초기 RLHF 모델은 몇 번의 대화 턴 이후 초기 지침을 잊어버리는 경향 -> Ghost Attention (GAtt)로 해결
- 대화 데이터셋에서 지침을 적용하여 대화를 제어
3.4 RLHF Results
3.4.1 Model-Based Evaluation
- 학습 잘되었다는 평가 (reward 모델이 사람 선호도 주석과 일치하는 것을 확인)
3.4.2 Human Evaluation
- 사람평가는 생략..
4. Safety
4.1 Safety in Pretraining
- "He" 대명사가 "She"보다 과대표현됨 (사전 훈련 중에 "He" 대명사를 "She" 대명사보다 더 많이 생성할 가능성이 있다는 점)
- 서구 중심의 경향이 나타났음
- 약 0.2%의 문서가 독성을 가짐
- 모델은 다른 언어에서 사용하기에 적합하지 않을 수 있음
- Llama2모델은 다른 언어에 비해 독성이 해소되지는 않음
- 모델의 편견과 사회적 이슈에 대한 이해를 위해 구체적인 컨텍스트에서 더 많은 테스트와 조치가 필요
4.2 Safety Fine-Tuning
- 지도 학습을 통한 안전성 세부 조정
- 안전성 RLHF
- 프롬프트로부터 더 안전한 모델 응답을 생성하고 이를 프리프롬프트 없이 세부 조정함을 포함
5. Discusstion
- RLHF의 흥미로운 특성(5.1절)에 대해 논의 : 생략
- Llama 2-Chat의 제한 사항: 생략
- 모델을 책임감 있게 공개하는 전략: 생략
6. Related Work
- 생략
반응형