목차
반응형
논문 정보
논문 제목: Neural Machine Translation by jointly Learning to Align and Translate
설명: RNN 기반
0. Abstract
- 기존 기계번역 방식은 통계적 방식
- 고정길이 벡터의 사용이 성능 향상을 막음
- qualitative analysis이 우리의 직관과 비슷함.
1. Introduction
- 기존 연구
- 인코더 - 디코더 형태의 연구가 성능이 좋음
- 인코더: 고정 길이로 벡터계산을 함
- 디코더: 인코딩된 벡터에서 번역해 출력
- 고정 길이 벡터는 긴 문장을 처리하기 어려움
- 해결방법
- 정렬하고 변환하는 방법을 배우는 인코더-디코더 모델
- 문장에서 관령성 높은 정보를 검색
- 인코딩에서 인풋 문장을 벡터의 하위 집합(a subset of these vectors)으로 선택함.
2. BACKGROUND: NEURAL MACHINE TRANSLATION
- 확률론적 관점
- 조건부 확률 문제
- arg max P(Y | X)
- 최근 LSTM이 영-프 번역에서 좋은 성능을 냄
3 Learning To Align And Translate
- 인코더, 디코더로 구성됨
3.1. Decoder: General Description
- 새로운 모델 정의 (조건부 확률식 이용)
$$p(y_i|y_1, . . . , y_{i−1}, X) = g(y_{i−1}, s_i, c_i)$$ - s 에 대한 정의 (시간 i에 대한 RNN 숨겨진 상태)
$$ s_i = f(s_{i−1}, y_{i−1}, c_i) $$ - c 에 대한 정의 (컨텍스트, annotaion h에 대한 가중합으로 이루어져 있음)
$$ c_i = \sum_{j=1}^{T_x}\alpha_{ij}h_j $$ - a 에 대한 정의 (annotaion h에 대한 가중치)
$$ \alpha_{ij} = \frac{\exp(e_{ij})}{\sum_{k=1}^{T_x} \exp(e_{ik})} $$ - e 에 대한 정의 (s는 RNN의 히든스테이트, h 는 input sentence)
$$ e_{ij} = a(s_{i-1}, h_j) $$
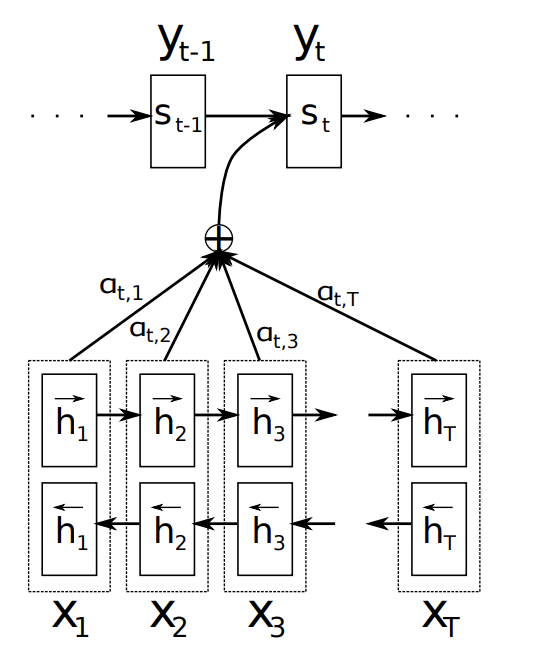
- a 설명
- 타겟 단어 y가 소스단어 x에 정렬되거나 번역될 확률
- s에게 h의 중요성을 반영
- 디코더는 주목해야 할 문장의 한 부분을 결정
- 소스 문장의 모든 정보를 고정길이 벡터로 인코딩 해야하는 부담을 줄여줌
3.2. Encoder: Bidirectional RNN For Annotaions Sequences
- 시퀀스 어노테이션을 위한 양방향 RNN
- 앞뒤 단어 모두 사용하여 요약해 어노테이션 계산
4. Experiment Settings
- 실험 세팅
- English-French parallel corpus
- ACL WMT '14.3 제공한 데이터
4.1. 데이터셋
- 단어를 348M 개로 제한, 가장 많이 사용하는 단어 사용
- news-test 2012, 2013을 이용해 학습 셋, 2014년 데이터로 테스트 셋 구성
- 토큰화 이후 가장 많이 사용되는 3만개 단어목록 사용
- UNK토큰 사용
4.2. 모델
- 첫 학습: 30개 단어로 된 문장
- 두번째 학습: 50개 단어로 된 문장
- 1000개의 hidden units
- 다중 레이어 네트워크를 이용해 각 단어의 조건부 확률을 구함
- Adadelta, SGD 사용
- 미니배치: 80개 문장
- 5일동안 훈련
5. 결과
- 생략
6. Related Work
- 생략
7. 결론
- 고정길이 벡터를 생성할 필요가 없어 관련된 정보에만 집중.
ps) 논문 내용을 python 코드로 구현한 내용은 만들게 되면 댓글에 링크를 달아놓을게요
반응형
'자연어처리' 카테고리의 다른 글
| [NLP] 토크나이저 (Tokenizer) (0) | 2023.07.07 |
|---|---|
| [자연어처리] GPT 4 논문 리뷰 (0) | 2023.05.09 |
| mecab 설치하기 (mac m1) (0) | 2022.12.13 |
| konlpy 설치하기 (mac m1) (0) | 2022.12.13 |
| [자연어처리] Transformer (NLP, 트랜스포머) 논문요약 (0) | 2022.11.29 |